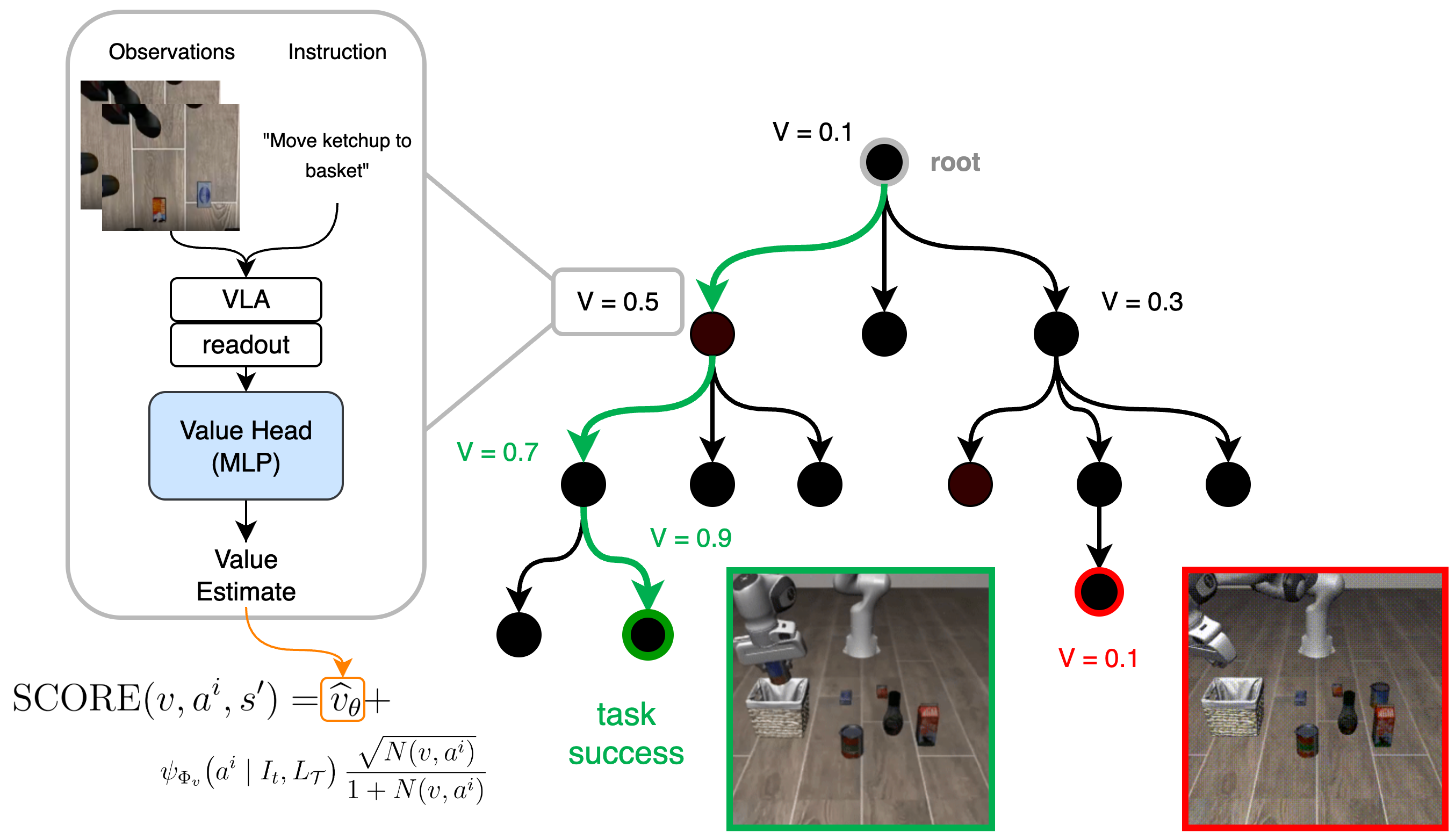
VLA models like Octo act reactively: at each step they map observations and a language instruction to an action chunk, without planning about future consequences. Under distribution shift or in long-horizon tasks, this brittleness causes hard-to-recover failures. Monte Carlo Tree Search (MCTS) addresses this by simulating candidate action sequences in a simulator before committing to one, but existing VLA-guided search (VLAPS) has no learned estimate of state value. Node selection relies only on the VLA action prior and a visit-count bonus, meaning if the policy assigns high probability to poor actions, the search has no way to detect this.
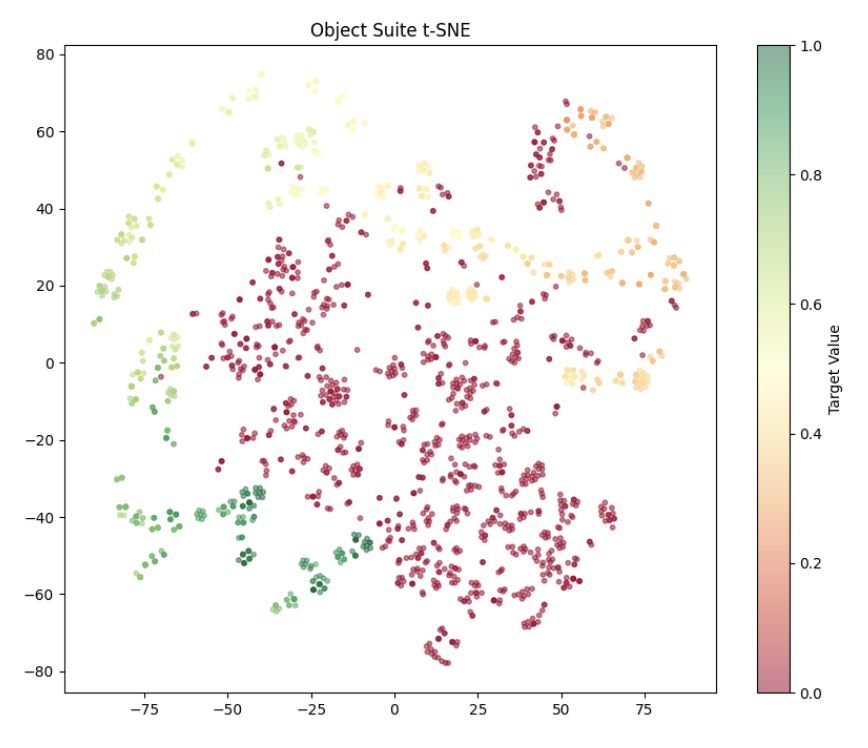
The key insight: VLA latent representations already encode task success/failure information. Prior work (SAFE) showed a small MLP probe on a VLA's frozen features can predict failure. We extend this from passive failure detection to active search guidance. A similar probe architecture, trained to predict Monte Carlo discounted returns, is fed into the PUCT scoring rule to bias the search.