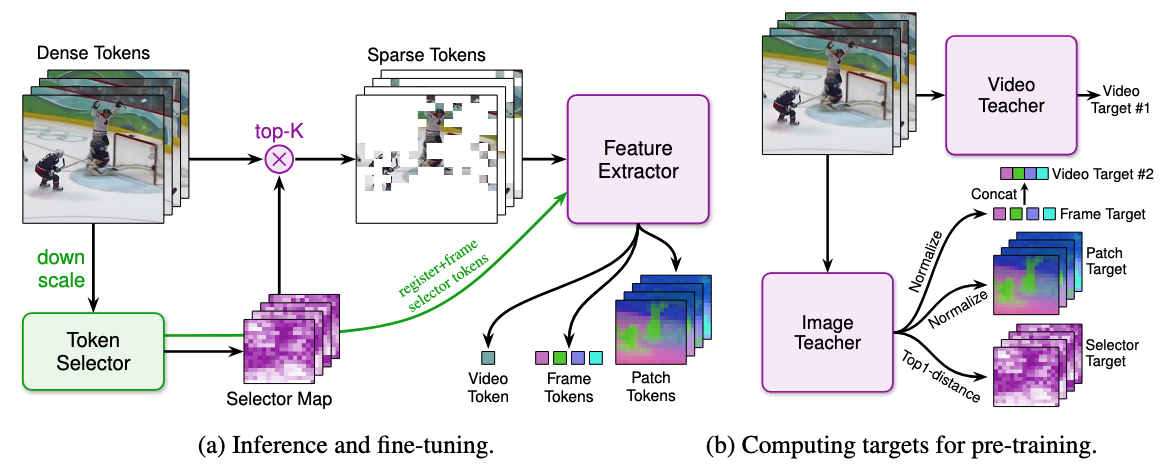
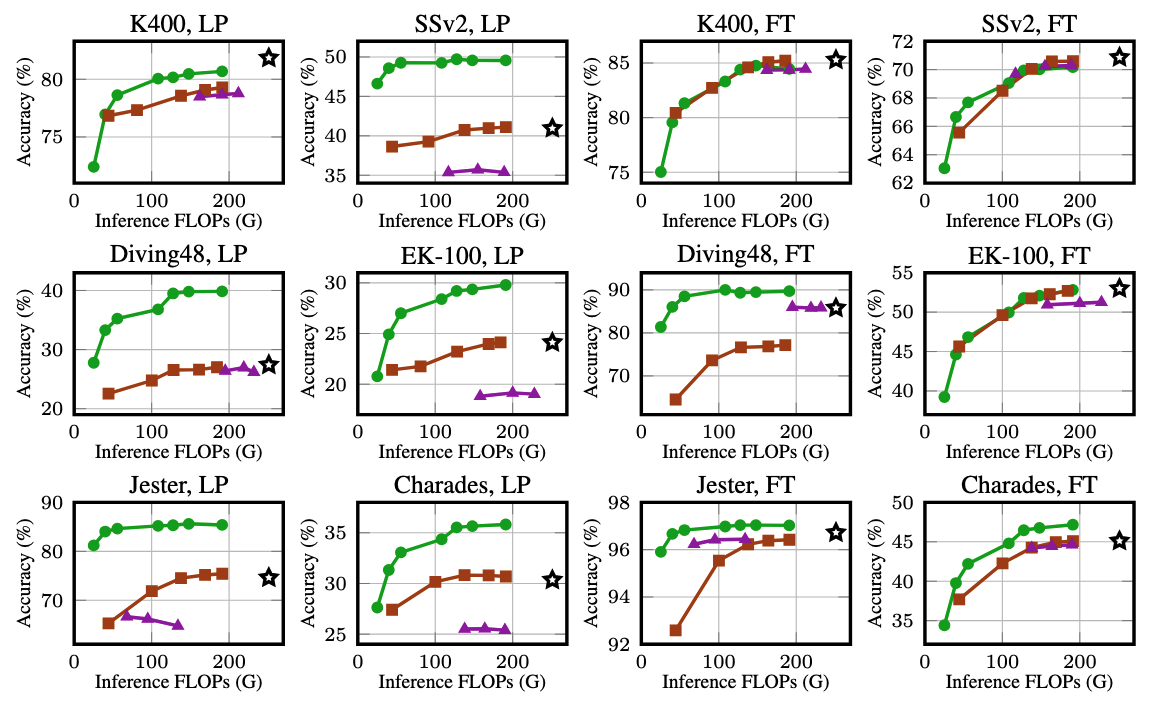
Video transformers split clips into space-time tokens and process them all with expensive, superlinear computation, yet most tokens are redundant. Static backgrounds, slowly-changing regions, and repeated frames all carry little new information. Existing token reduction methods (ToMe, RLT, vid-TLDR) still process all tokens in early layers before merging or pruning, limiting efficiency. Others skip tokens but cannot recover accuracy at high sparsity.
The key question: which tokens actually matter, and can we decide before running expensive layers? Our answer is to train a lightweight, low-resolution selector that scores every token for uniqueness, and to only run the deep extractor on the selected top-K.